

Modern Big Data Platform – why do enterprises choose Databricks? (part 2)
This time, I would like to highlight the details related to developing a Big Data solution and what Databricks features make it a robust development ecosystem.

In the first part of this article, I write about the enterprise architecture-related reasons why companies consider Databricks as a suitable Big Data platform. This time, I would like to highlight the details related to developing a Big Data solution and what Databricks features make it a robust development ecosystem. There are the following areas which I consider important:
the development environment focused on the Databricks workspace,
the Delta Lake component that replaces a good old Hive,
infrastructure provisioning, automations, and management.

Databricks development environment
The main gateway to Databricks that I use every day for development is Databricks Workspace – a user-friendly and highly intuitive web application. This is where you can view your workflows, job runs, preview logs, and access the Spark UI. There, you can view the compute clusters and their configuration, as well as all the autoscaling events happening on the clusters. Workspace is also a place where you can write and run SQL queries, which are important for basic profiling or identifying data-related issues. Of course, Databricks provides you with a JDBC connector so you can also open connections and execute queries from your favorite SQL client or programming IDE directly. Still, doing this from your browser may be convenient.
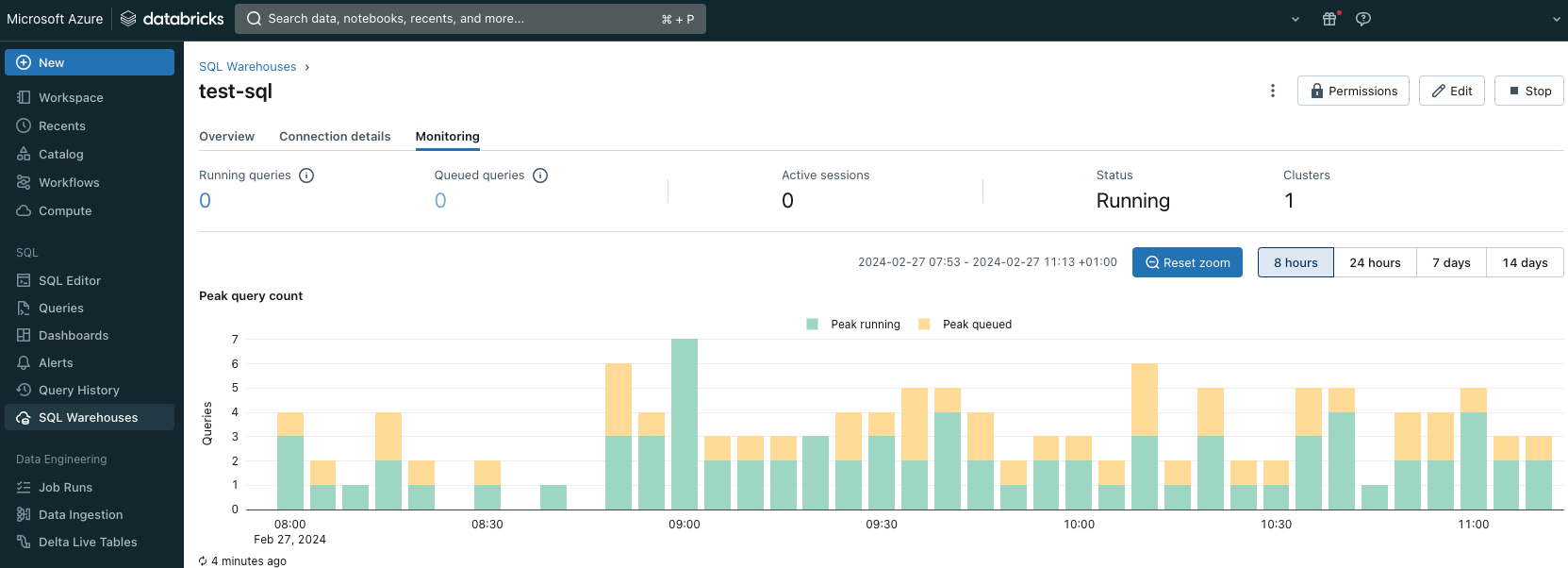
The workspace provides you with access to notebooks. You can write the Spark code in the notebook using multiple languages (Scala, Python, R, SQL). Notebooks are a perfect experimentation environment and, in fact, can be used similarly to the Spark Shell. In case you need to prototype something or debug on the cluster, you can quite easily write a code that can be run directly on the cluster and access the data in your tables. However, it is also possible, and even recommended by Databricks, to encapsulate the notebook into a workflow and use notebooks to run code even in a production setup. For many programmers, that could actually sound like a nightmare, but if you think about it, it could be a valuable feature, especially when integrated with your code repository.
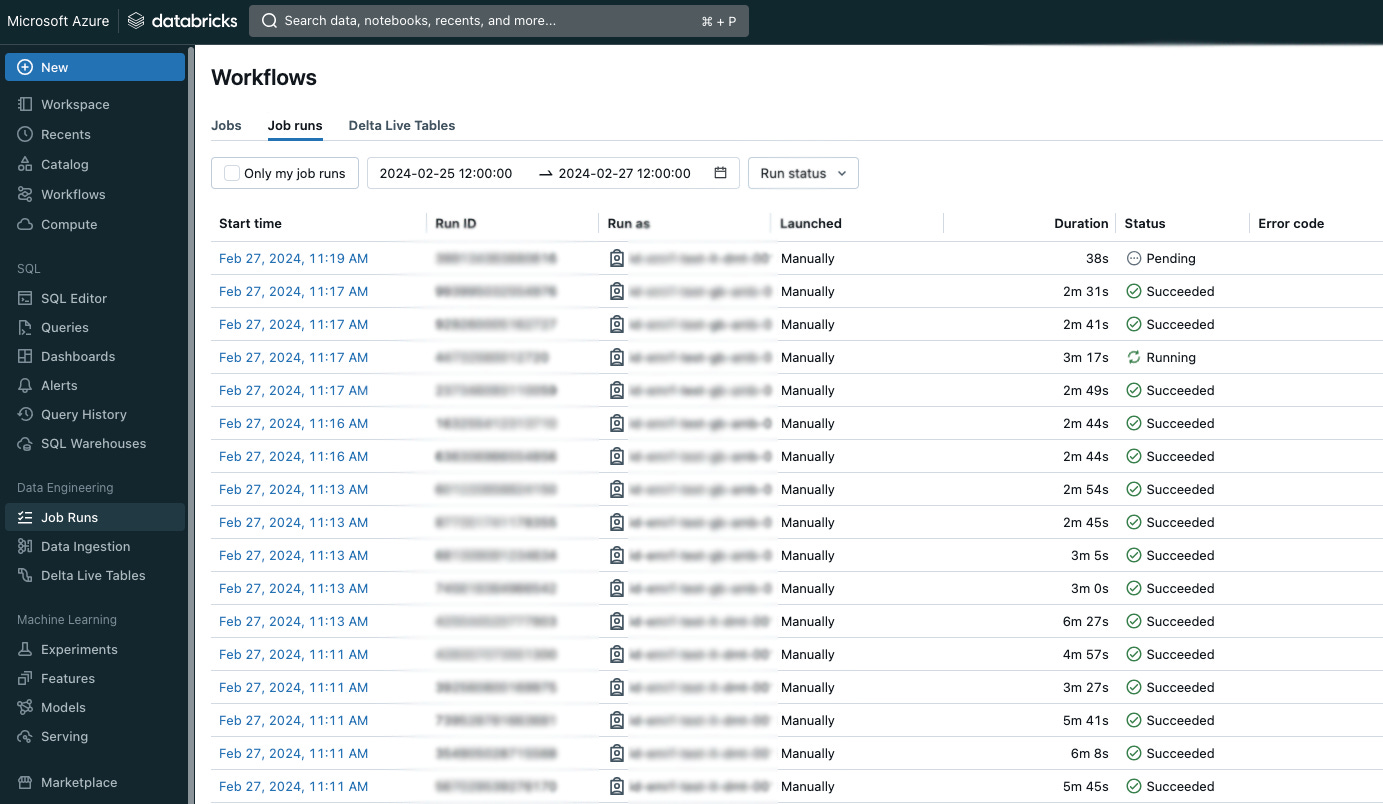
Other than that, the workspace provides the visualization and dashboarding capabilities. There is also Machine Learning integration that covers model registry and serving capabilities, making Databricks Workspace a powerful and convenient development environment. It is clearly visible that Databricks invests in additional data-related features to make a fully operational data platform that can support all big data, data engineering, and data science use cases.
Ok, but what are the overall benefits of this tool? I am sure that for many of you, especially programmers, these are the features you could easily get by using alternative tools. The majority of those features are available in the classical Hadoop ecosystem anyway, just in a more vintage style. None of these capabilities are a game changer? I do agree.
Delta Lake
Another thing you get after switching from Hadoop to Databricks is the Delta Lake technology. Delta Lake is, in fact, a replacement for Hive and Impala that brings a set of important improvements. The key things you get are the following:
ACID Transactions – Delta Lake provides ACID (Atomicity, Consistency, Isolation, Durability) transactions, which are crucial for maintaining the consistency and reliability of data.
Schema evolution – you can evolve your schema over time and enforce it, which is not so straightforward with Hive.
Time Travel (data versioning) – you can roll back and restore your table to one of its previous versions. Thanks to the built-in versioning, compliance requirements are easily met.
Optimize for Spark – Delta Lake is fully compatible with Spark and designed with Spark in mind. It offers many options to control the performance of your Spark workloads.
Databricks Unity Catalog – it replaces the traditional Hive metastore, simplifying access and metadata management; also, it plays an important role in performance optimizations.
All the above features make the Delta Lake technology a favorable successor to Hive, and at the moment, this is a more convenient way to store data when using Spark. You don’t have to invalidate metadata tables anymore, just to mention one of many benefits after moving to Delta. Of course, when migrating from traditional Hadoop, you may encounter some small inconsistencies, such as issues with concurrent updating of partitions that have to be more carefully controlled in your code. But overall, this change is beneficial. Databricks is constantly investing in Delta to make it an even more powerful data store. Databricks is often mentioned as a direct competitor of Snowflake due to its constantly improved SQL support or, to be more precise, its interface for executing SQL queries on Spark.
Infrastructure management
But neither the development ecosystem nor Delta Lake can be compared to the last set of features I want to describe. They are related to infrastructure management and its decent simplification.
Databricks is cloud-native, and it leverages the benefits of cloud infrastructure. The compute clusters are designed to autoscale based on the size of the workload. Of course, the clusters do not grow infinitely but rather according to predefined policies. This is usually configured by DevOps teams using the Terraform scripts. In the policy, we define the size of the instance/machine the clusters should be built of, certain permissions, and auto-scaling behavior (limits, time after which a cluster scales to zero, and more). After granting access to the policies to the developers, they are allowed to create the compute clusters for their jobs or notebooks using Databricks Workspace.
With the above comes another important advantage – computational isolation. Each job, notebook, or developer can have a dedicated cluster created that exclusively supports a given workload. If the cluster is not used for some minutes, it scales to zero and costs you nothing. As a result, enterprises that experience processing peaks and suffer from resource cannibalization for their on-premise data centers can benefit from dynamic scaling and are not affected by increased computation resource demands. This is a huge game changer and a real benefit. What is even more beautiful, if your policies are configured properly, this will not cost you more than on-premise infrastructure and traditional Hadoop clusters.
All the Databricks artifacts, such as clusters, workflows/jobs, and everything related to permissions, are supported by APIs that are perfect for automating the deployment of Spark pipelines. Your CI/CD pipelines can update the versions of your code executed by the Databricks workflows each time the new code is built. You can spin up new Databricks workspaces or automate new project setups within the workspaces. The ability to manage this on a daily basis is another game changer that can ultimately significantly reduce maintenance costs.
Conclusion
Databricks offers a highly convenient environment for working with Spark when processing Big Data. Development environment is modern and user-friendly. You can perform a lot of tasks without leaving the web browser. The whole set of APIs and modern (or, if you prefer, DevOps-centric) approach to maintaining the workspaces, projects, and underlying infrastructure makes it more convenient to efficiently deliver Spark pipelines. And all of those do not have to be more expensive than on-premise Hadoop clusters. Databricks should be considered by Spark-based organizations as the next platform to migrate to after Hadoop.